决策树的个人理解
分类: 人工智能、学习笔记 2001 2
决策树
所谓决策数,多个特征,对于每个特征进行评估,对于结果为True和False分别进行处理,处理完之后,在当前的处理结果的基础上,在评估其他特征,直至评估完成。
特征的处理顺序选择
1. 信息增量
熵:混乱程度
信息熵:纯度
信息增量:
决策树的生成:
如现有abc三个特征,其中a特征有三种分类:a1,a2,a3,b和c也对应有三种分类。那么假如数据在a的分类已完成,那么需要分别对a1、a2、a3的分类结果进行下一步的处理。处理过程如下,纯属个人描述,自己慢慢品:
- 首先计算在处理完a1的情况下,以b作为切割属性,对应的信息增量(Gain)为0.2,而以c作为切割属性,对应的信息增量(Gain(D,a), 其中D为原有数据,即就是在处理当前特征的根节点数据,a为按哪列划分)为0.5,那么在a1做完处理之后,下一个判断属性应该是c。
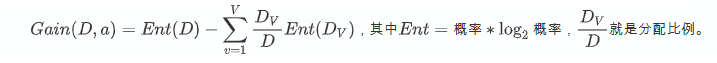
公式理解:a有v中分类,Dv是分类v所包含数据量,D为总数据量。
- 计算处理完a2的情况下,以b作为切割属性,对应的信息增量(Gain)为0.8,而以c作为切割属性,对应的信息增量(Gain(D,a), 其中D为原有数据,即就是在处理当前特征的根节点数据,a为按哪列划分)为0.1,那么在a1做完处理之后,下一个判断属性应该是b。
决策树的生成
- 当某分类的数据全是同一种类型
2. 信息增益率
信息熵

信息增益率Cain_ratio(D, a)
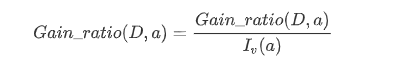
因此Iv(a)就是Ent(D),就是a相关的信息熵。
用法:
同样,在选择特征时优先使用信息增益率大的特征。从式子可以看出来的是分割的种类如果太多的话,Iv(a)也即是更小。而信息增益率会更加倾向于取值数目比较多的内容。所以先找信息增益中几个比较大的增益特征,判断他们的增益率,找最大的增益率。
3.基尼指数
基尼值
,指的是连续两次抽取相同分类的概率
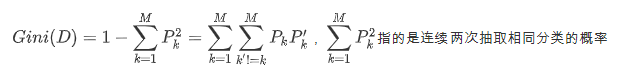
p1的平方是指抽取两次都出现1的概率。
所以基尼值就是连续两次都抽取到不同分类的概率。如果基尼值大,则纯度低。
信息熵大,则纯度低。
基尼指数
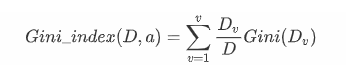
基尼指小,代表纯度越高
共 2 条评论关于 “决策树的个人理解”