浅析 集束搜索(Bean Search) 算法
分类: 人工智能、学习笔记 2280 0
集束搜索(Bean Search)
背景
场景一:如果说,你想实现:输入一段语音片段,经过一一列操作,实现最后输出语音的内容。再此过程中,假如你不想随机输出一些结果,而想得到最好最优的输出结果,此时,则需要本算法。
场景二:实现机器翻译,输入一段法语,输出一段最有的翻译结果。
方法:
1. 使用的网络:
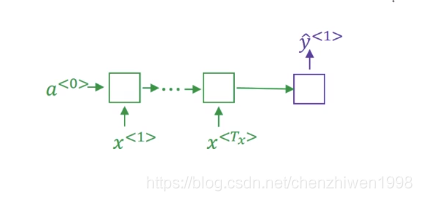
2.词典

3.思想
与贪心算法不同,集束算法含有一个变量b(bean width), 用来存放在一次搜索中,搜索多少个可能的结果。例如:
第一步:
在搜索第一个词时,结果可能会输出最有可能是第一个词的三个可能值:a , jane , september, 然后将结果存储到内存中;
原理:
通过将网络中编码的结果,输入到解码网络中,解码网络的第一个输出结果<y^1>,即就是编码网络的10000个词中可能性最大的前三个。
第二步:
在第一步的基础上,以第一步的三个结果为句子开头为条件,预测在含有10000个词的词典中是第二个词的可能性最大的前三个。
原理:
首先将词典复制三份,第一步输出的三个结果,分别对应一份词典,从而在自己对应的词典中找出最有可能是第二个词的三个词。即找出最有可能成为前两个词。其概率为:
最有可能成为第二个词的概率:p(y^2 | x, y^1)
最有可能成为前两个词的概率:
P(y^1, y^2 | x) = p(y^1 | x) * p(y^2 | x, y^1), 其中y^1 = ‘a’;
P(y^1, y^2 | x) = p(y^1 | x) * p(y^2 | x, y^1), 其中y^1 = ‘jane’;
P(y^1, y^2 | x) = p(y^1 | x) * p(y^2 | x, y^1), 其中y^1 = ‘september’;
第二部的结果可能是:
- a zulu
- jane in
- jane a
注:
- 在第二步中,一共有b * len(词典) 中选择,即 3 * 10000 = 30000 个选择。
- **在第二步的结果中,并不一定包含第一步的结果。**即:在第二步的结果中,是综合考虑了前两了词,使得前两个词的可能性最大,所以不一定是3个第一步的结果和三份词典中的某三个词的组合使得成为句子前两个词的概率最大,很有可能是第一步的结果中的某一个或两个词与第二部中词典中的某三个词进行组合,使得成为句子前两个词的概率最大。
说的可能比较绕,但是,仔细思考,还是可以理解的。终归一句话第一步的三个结果并不一定是最终结果三个句子的的首单词。
第三步、…… 和第二步类似。
这样就可以最后得到有可能的三个值,但是,此处的三是认为设置的b的值,在设置b的值时,请按实际情况设置。
最终得到一个最有的结果。
共 0 条评论关于 “浅析 集束搜索(Bean Search) 算法”