自注意力机制(Self-attention)
分类: 人工智能 2306 0
自注意力机制(Self-attention)
背景
最近,学了好多东西,今天看了一下李飞飞老师讲解的自注意力机制,因此在这记录一下,以供日后复习,同时自己学习消化知识也好。
综述
一般来说,模型的输入输出有三种:
-
- N个输入,经过模型计算后,输出N个结果,也就是对输入向量进行计算,从而得到每个向量对应的输出值。
- N个输入,送入模型进行计算,最终得到一个结果。这就是平时常见的比如,文本分类、情感分析等。
- 任意个输入,输出任意个输出。这种在生活中也较为常见,比如机器翻译,对于一句话,不同的语言会包含不同个词。
此文先讲讲第一种,也就是说N个输入,得出N个结果,这种模型一般形式如下图所示。
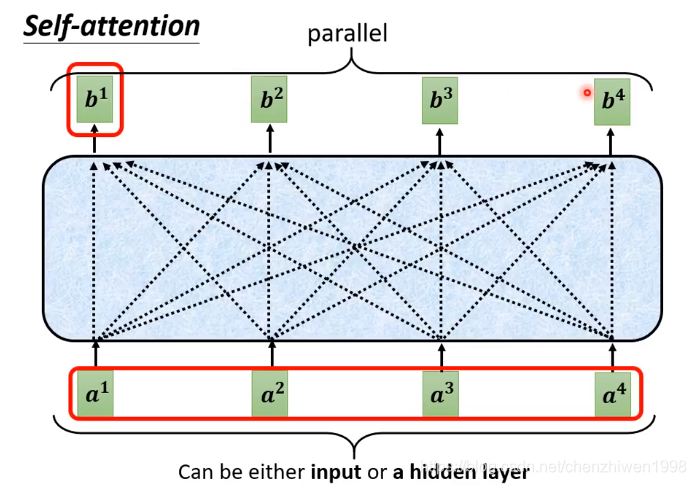
![]()
在图中可以看到,a表示对输入数据进行处理之后,作为self-attention的输入,从而得到b。其中,在得到每个b的过程中,都会考虑到输入的每个元素,包括a1, a2, a3, a4。这样对于输出的结果更合理。
对于中间那一块深色的模块,就是自注意力机制的核心。在注意力机制中,首先需要计算注意力得分,比如:在进行计算第一元素时,需要考虑其他三个元素的情况,在计算第一个元素时,分别考虑其他每个元素的权重,给每个元素打分,重要性越大则分数越高。
其计算得分的流程如图下所示。
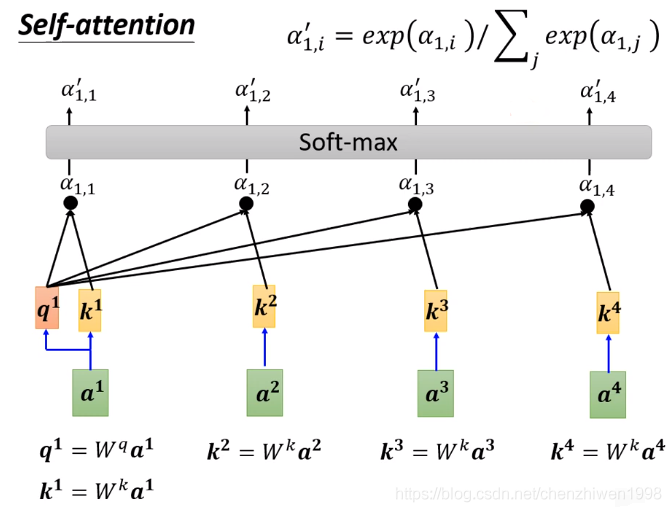
![]()
在上图中可以得到,自注意力机制在计算第一个元素时流程为:
-
- 首先,给输入向量每个元素,分别乘以两个举证Wq和Wk,从而计算出q1和ki。
- 然后,将q1和ki分别相乘,得到每个元素的分数。
- 为了得到更好的结果,对每个分数进行一次soft-max。
最后,将每个分数按图上公式进行计算,得到输出在计算每个元素时,对应考虑其他元素的注意力分数。
在得到分数之后,可以通过以下图得到b,具体如下图所示。
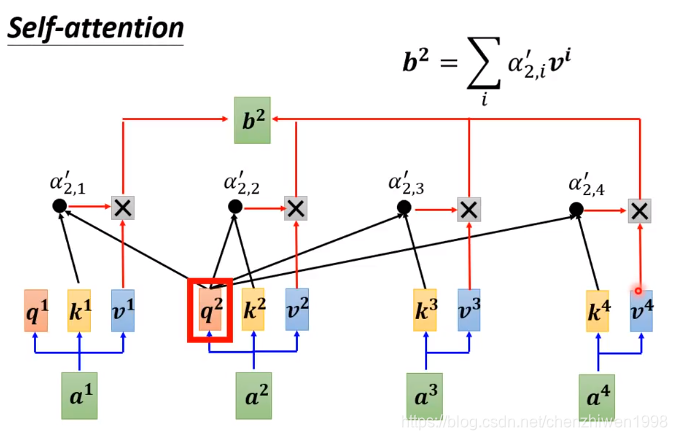
![]()
在上图中,结合计算注意力得分的图,可以看出,在得出注意力分数之后,在将分数和vi进行相乘之后,再进行加权求和,即可得到b1。用同样的分数可以的b2,b3,b4。
矩阵形式
为了方便计算,一般会通过矩阵形式来计算,如图所示。
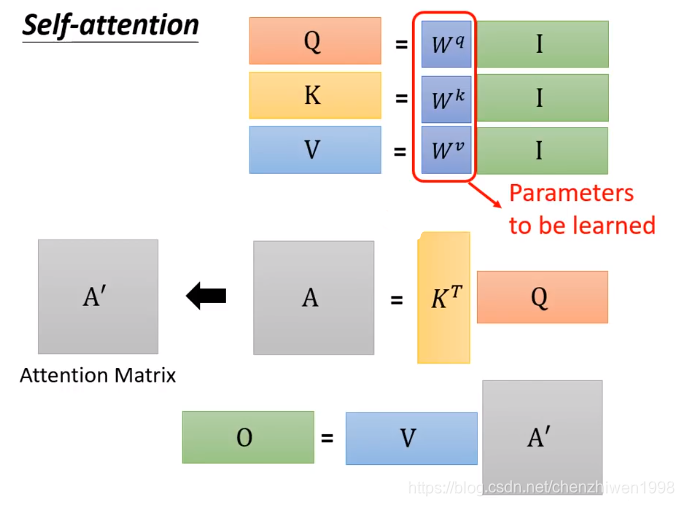
![]()
在上图中可以清楚的看到,在进行自注意力中用矩阵形式进行计算过程。
其中I为输入向量进行拼接后的举证,Q、K、V矩阵为每个输入向量对应的q、k、v进行拼接后的矩阵。
共 0 条评论关于 “自注意力机制(Self-attention)”