Transformer 网络
分类: 人工智能、学习笔记 2179 2
Transformer
从整体框架来讲,Transformer其实就是encode-decode框架,即就是编码解码。只不过在编码和解码的内部比较复杂,经过了多次复杂计算。
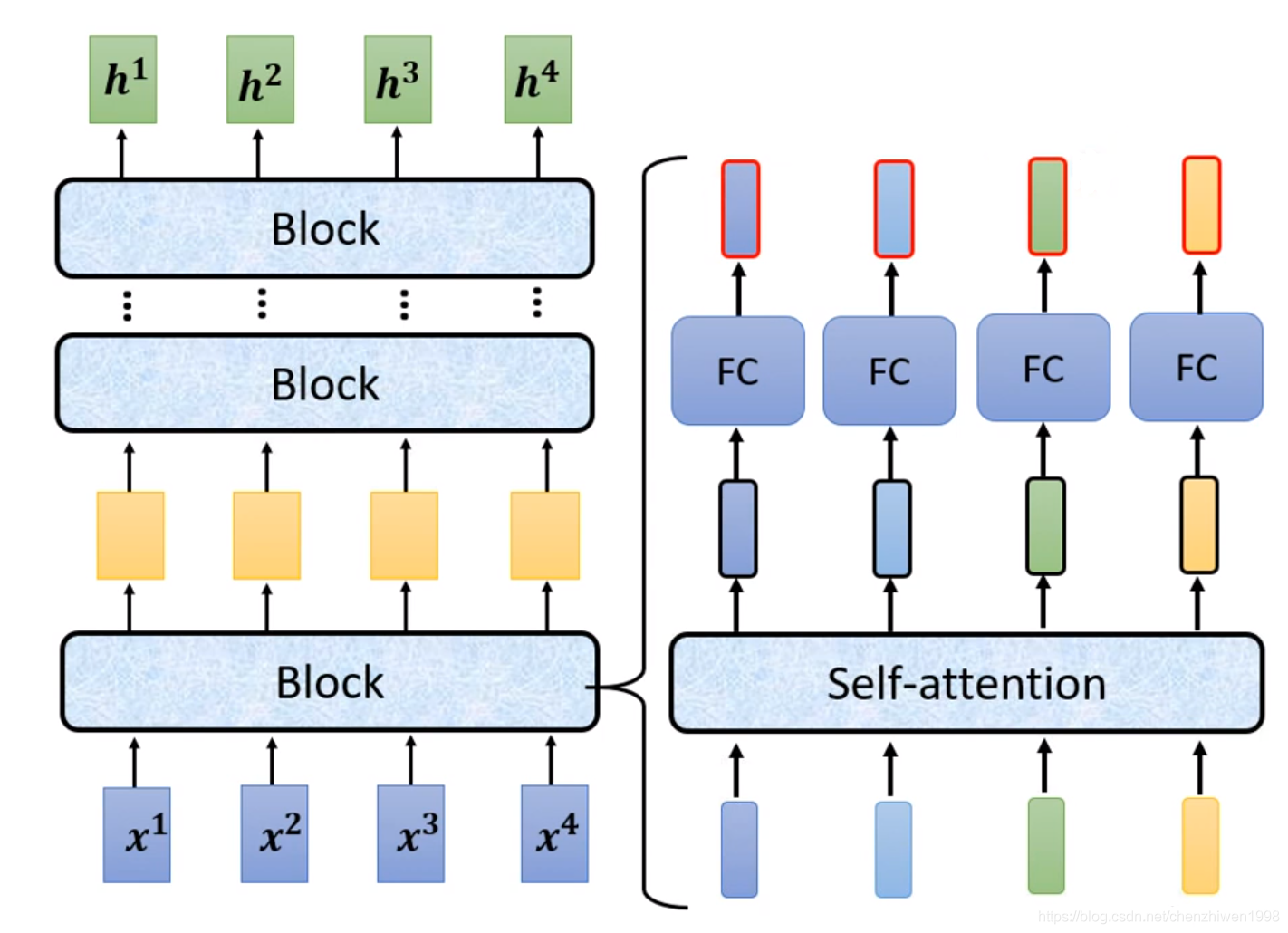
比如说,encode编码阶段,其内部整体框架如图所示。
![]()
在图上可以看出,首先输入所有的向量,然后经过多次block的计算,最终得到相同数量的输出结果向量。其中每个block内部包含一层自注意力机制、一层全连接层。同样,在自注意力机制中,计算每个向量时都会考虑其他元素。区别是,在transformer的自注意力机制结束后,不是直接送入下一层,而是将自注意力机制的结果和输入向量相加后再送入下一层。
Encoding 编码
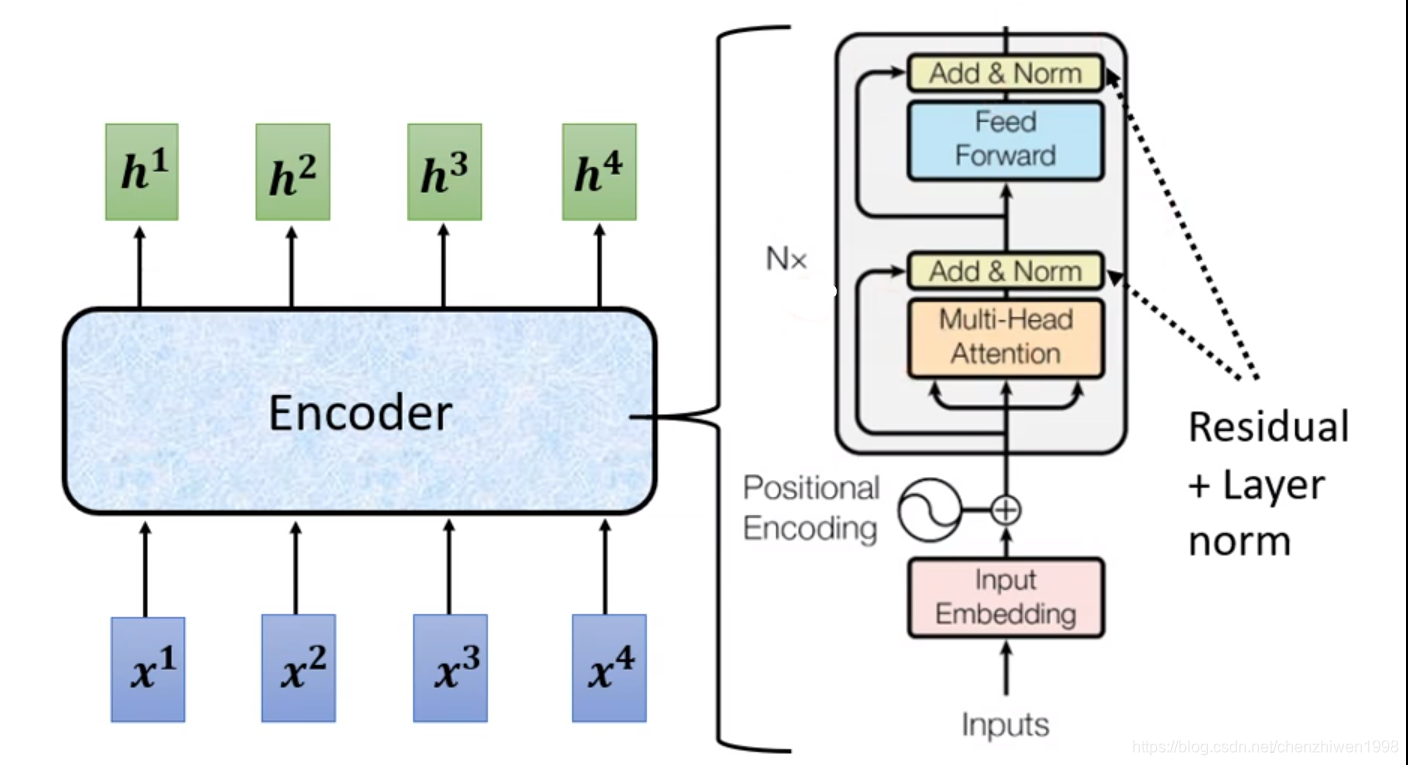
其中,详细来讲,整个encode的详细计算过程如图所示。
![]()
在上图中,其右侧为官方所给出的encoding内部的结构。其过程为:
-
- 首先,将输入向量输入到embedding中,从而得到embedding后的结果,然后加上位置编码结果。
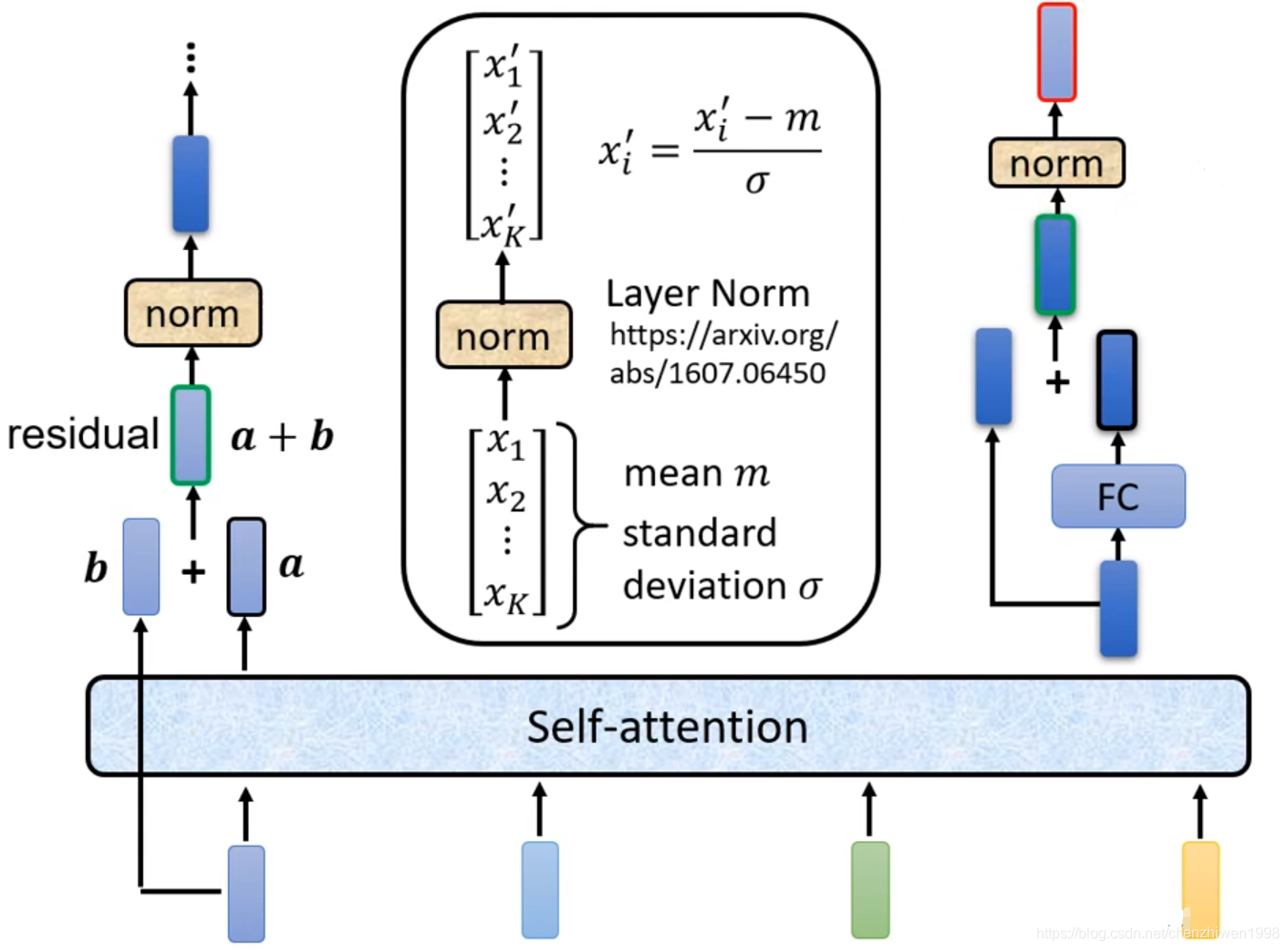
- 再将结果送入block。再block中首先进行多头注意力机制,然后将执行Add & Norm,Add & Norm指的是首先执行Residual,而Residual如下图所示,指的是将自注意力机制的结果和输入向量进行相加,其结果为residual集合。
- 然后进行layer norm操作,该操作如下图所示,输入一个向量则对应输出一个向量,在此过程中首先计算输入向量的均值、方差,以及标准差,然后根据以下公式
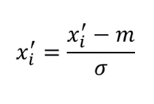
 分别计算norm后的结果。
分别计算norm后的结果。 - 最后,将结果送入全连接层,同样再进行一次Add和Norm操作,输出结果向量,编码阶段完成。
![]()
Decoding 解码
整体而言,以语音识别为例,再解码阶段,首先将编码结果作为输入,具体过程:
-
- 第一步:自定义一个指定符号的开始字符,和编码结果一起输入到解码器中,解码器会输出结果再进行一次softmax,最终输出一个结果向量,向量值为第一个词是词库里每一个词的概率,其最大概率所对应的字符即为第一个词。
- 第二步:将第一步的记过作为输入,输入到解码器中,用同样的方法得出第二个值,一次类推,最终得到输出结果。
具体如下图所示。
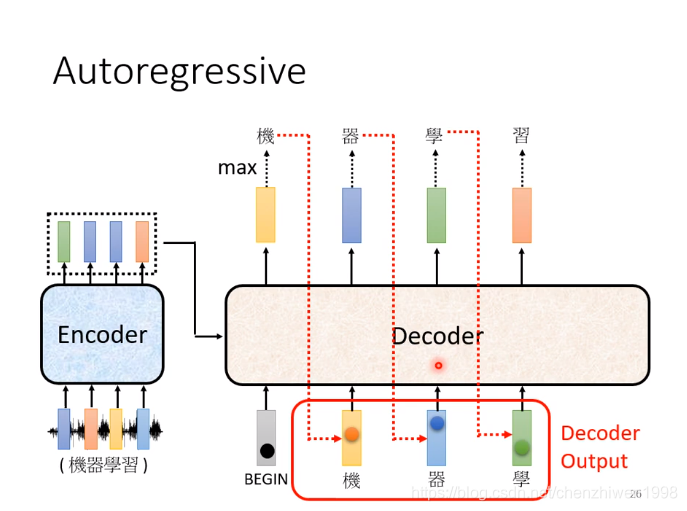
![]()
解码过程中,官网所给出的详细解码过程如图所示:
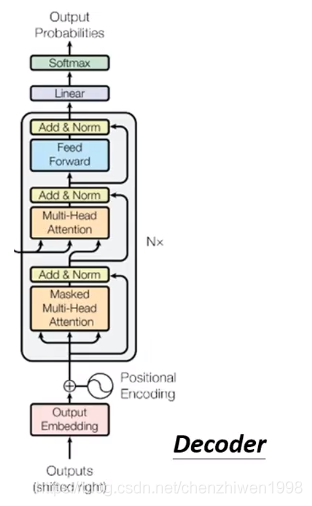
![]()
整体上看,和解码过程非常的类似,区别就是再解码过程中多了一层Masked注意力机制。Masked self-attention的核心是:在计算每一个元素时,并不是和之前一样考虑所有的输入元素,而是只考虑当前计算元素之前的元素,并不考虑还未计算的元素。如下图所示。
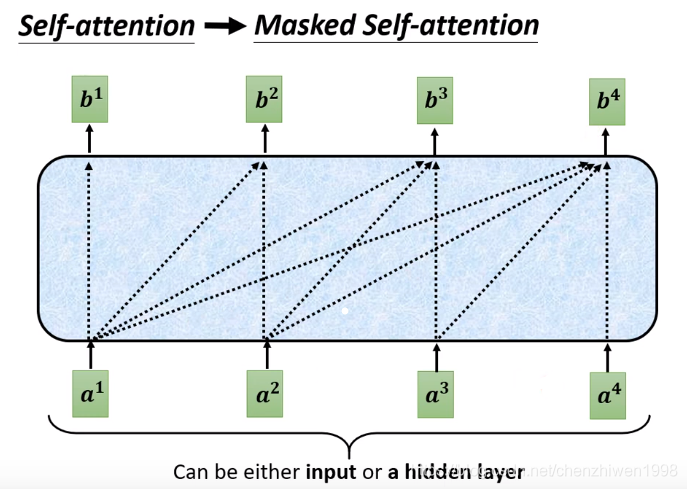
![]()
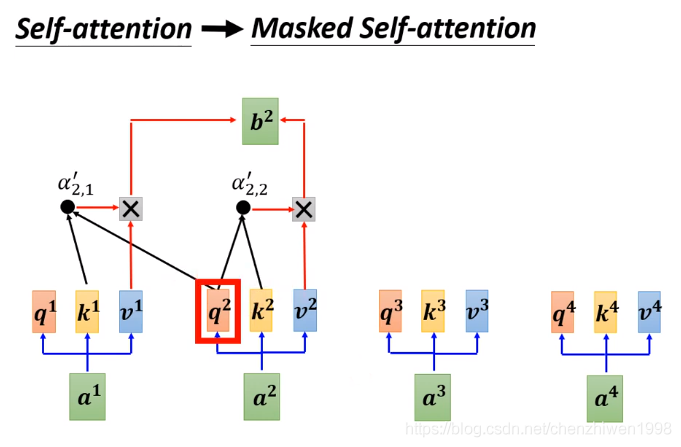
![]()
在上图左图中可以清晰的看到,在计算b1的时候,不考虑任何元素,因为在计算b1时,还未生成任何元素,即就是a1之前没有其他输入元素。在计算b2时,只考虑a2前面的元素a1,而不考虑a2之后的元素(a3, a4)。同样计算b3时,只考虑a1, a2而不考虑a4。计算过程如上图右图所示。其实也很好理解,在解码阶段中,当计算a2时,a3和a4并未生成。
编码->解码
在整个transformer中,分为编码和解码阶段。其中在解码阶段的中间一个block(如上面解码框架图所示)中,包含编码的两个输入和解码阶段第一个block的输出结果,一起输入到中间的block。如下图中蓝色圈所示。整个block称为cross attention。
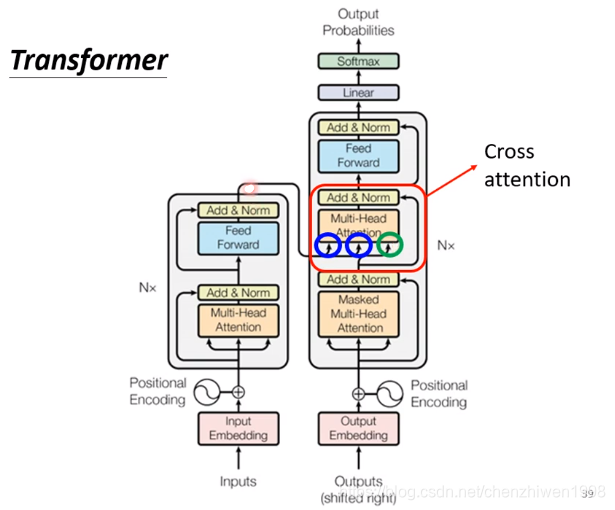
![]()
在cross attention中,具体计算如下图所示,首先,从编码的输出结果中计算得出ki和vi,在通过将解码阶段第一个block的输出结果计算得到q,然后,使用ki和q进行一定的得分运算,得到权重分数后将所有对应的vi和得分进行加权求和得到最终结果,送入到第三个block,即全连接层。
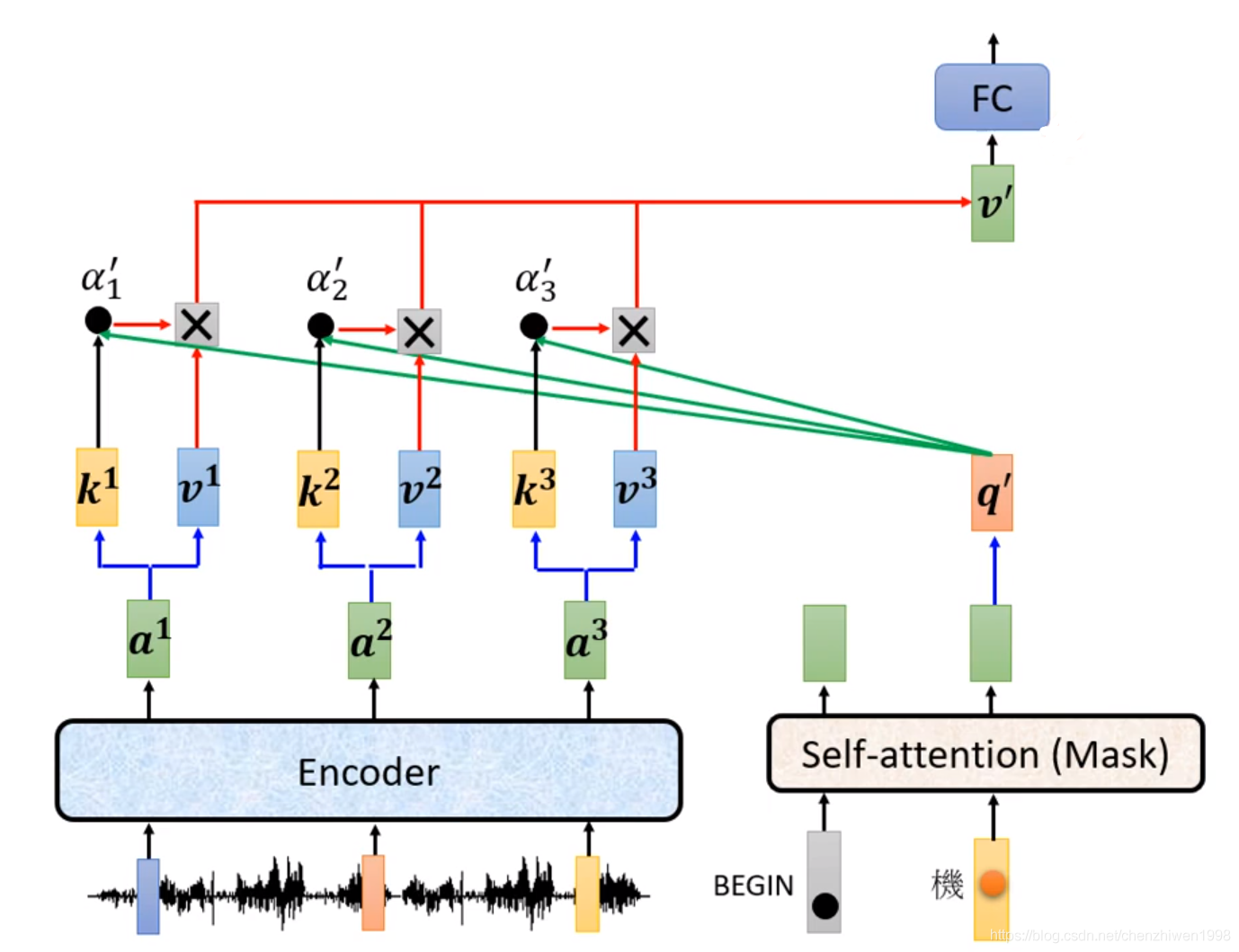
![]()
总结
以上就是对于本次学习的整个过程,在自然语言处理里transformer网络使用较为普遍,所以在此记录一下,以供日后学习和复习,存在问题的话记得留言指出。
共 2 条评论关于 “Transformer 网络”