论文阅读–Semantic Grouping Network for Video Captioning
分类: 人工智能、学习笔记 2445 0
Semantic Grouping Network for Video Captioning
abstract
提出了Semantic Grouping Network(SGN)网络:
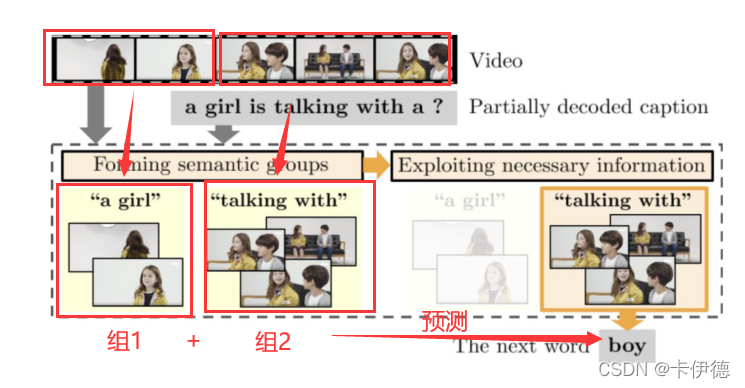
- 用部分已经解码的字幕中,选择可可以区分的单词短语对视频帧进行分组,也就是将表达不同意思的帧分组(与聚类相似);
- 对语义对齐的组进行解码,以预测下一个单词;(根据前面的已经生成的、分好组的词预测下一个)
以前:丢弃或者合并重复视频信息
SGN:检索最有鉴别能力的单词短语,然后将这些词与视频帧关联 。这样可以让语义差不多的帧聚类在一起。
贡献:
- 新方法:先分组视频帧,再生成描述
- 新损失:对比注意力损失,可以在不需要人工标注的情况下,实现单词短语和视频帧之间的准确校准。
Introduction
语义群(组)条件:
- 语义组的意思应该是具体的、可观察的,不能是is、the之类的;
- 语义是可区分的;
- 语义和视频帧之间对应;
贡献:
- 提出了一种语义分组网络,并提出了新方法(根据分好组、已经生成的词预测下一个)
- 提出对比注意力损失(CA loss)
- 在常用数据集超过了当前最好的模型。
Semantic Grouping Network
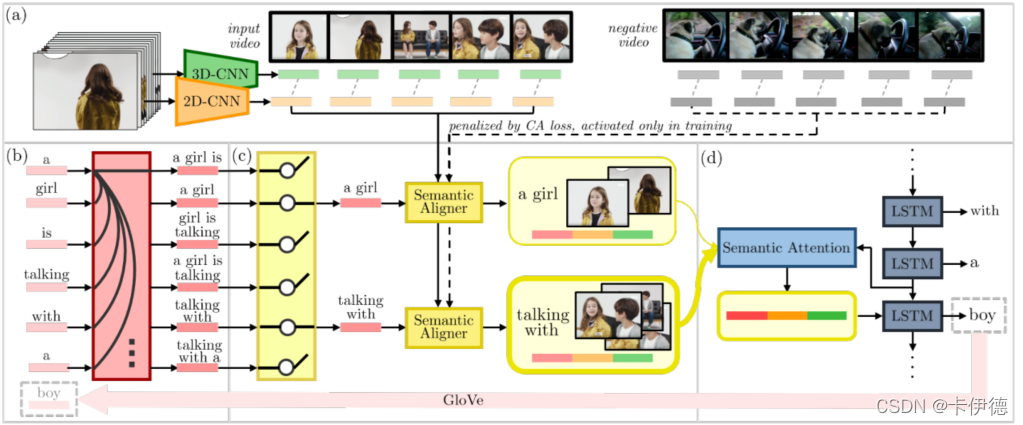
结构:Visual Encoder、Phrase Encoder、Semantic Grouping、Decoder、Contrastive Attention (CA) loss
Visual Encoder 视频嵌入
获取视频并为每个视频帧生成帧表示。
Phrase Encoder 处理单词为短语
接受部分已解码的标题,并生成由标题中的一组单词组成的短语(组合单词生成短语)
Semantic Grouping 分组(视频帧+筛选后短语)
过滤出相似的短语,并通过围绕前面处理后的短语与视频帧之间对应,构建语义组(处理前面Phrase Encoder生成的短语)
Decoder 根据分组预测下一个词
解码器利用语义组来预测部分解码的标题的下一个单词
数据集
- MSR-VTT
- MSVD
共 0 条评论关于 “论文阅读–Semantic Grouping Network for Video Captioning”