视频行为识别(二)——小样本动作识别的分层组合表示
分类: 人工智能、学习笔记 2811 2
Hierarchical compositional representations for few-shot action recognition
文章于2023年发表于CVPR会议上的一篇论文。该会议是计算机视觉任务中的TOP会议。
论文地址:https://arxiv.org/abs/2208.09424
开源地址:暂未开源(重点是Idea)
文章创新点
1. 核心工作
提出了一种新的分层合成表示(HCR)学习方法,用于少数镜头动作识别。具体而言,就是利用层级聚类将动作划分为多个子动作,并进一步分解为细粒度的空间注意力动作(SAS动作)。理论依据是是动作识别任务中新动作类型和基本动作类型之间在子动作和细粒度SAS动作之间有着相似之处。此外,利用Earth Mover’s Distance衡量了视频样本间子动作的相似性。
2. 思路
在视频中虽然训练时的基本动作和测试时的新动作之间存在很大的差距,但它们可以共享基本SAS动作,比如HMDB51数据集中几乎所有的视频都包含了胳膊移动的动作。因此,该论文从丰富的基本类动作中概括出细粒度的模式,并将它们转移到学习新动作类别中。这些细粒度的模式可以帮助为分类提供跨类别的有区别的和可转移的信息
3. 贡献
(1)提出了分层表示的细粒度子动作和SAS动作组件,这能够学习新动作和基础动作之间更多的共同模式;
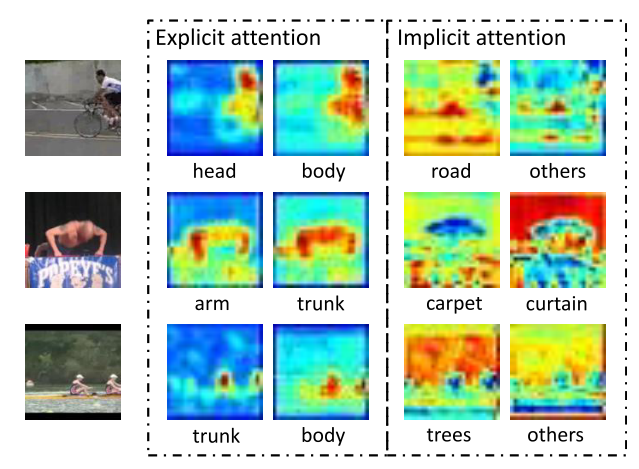
(2)设计了部件注意模块(PAM),以关注各种感兴趣的区域,特别是,明确的SAS行动包含预定义的人体部位和隐含的SAS行动包含其他行动相关的线索,如上下文。
(3)为了更好地比较细粒度的模式,采用地球移动器的距离作为距离度量的几杆动作识别处理时间无关的行动,它可以很好地匹配这些细粒度和歧视性的子动作表示。
(4)大量的实验表明,所提方法在HMDB51,UCF101和Kinetics数据集上取得了最先进的结果。
模型结构
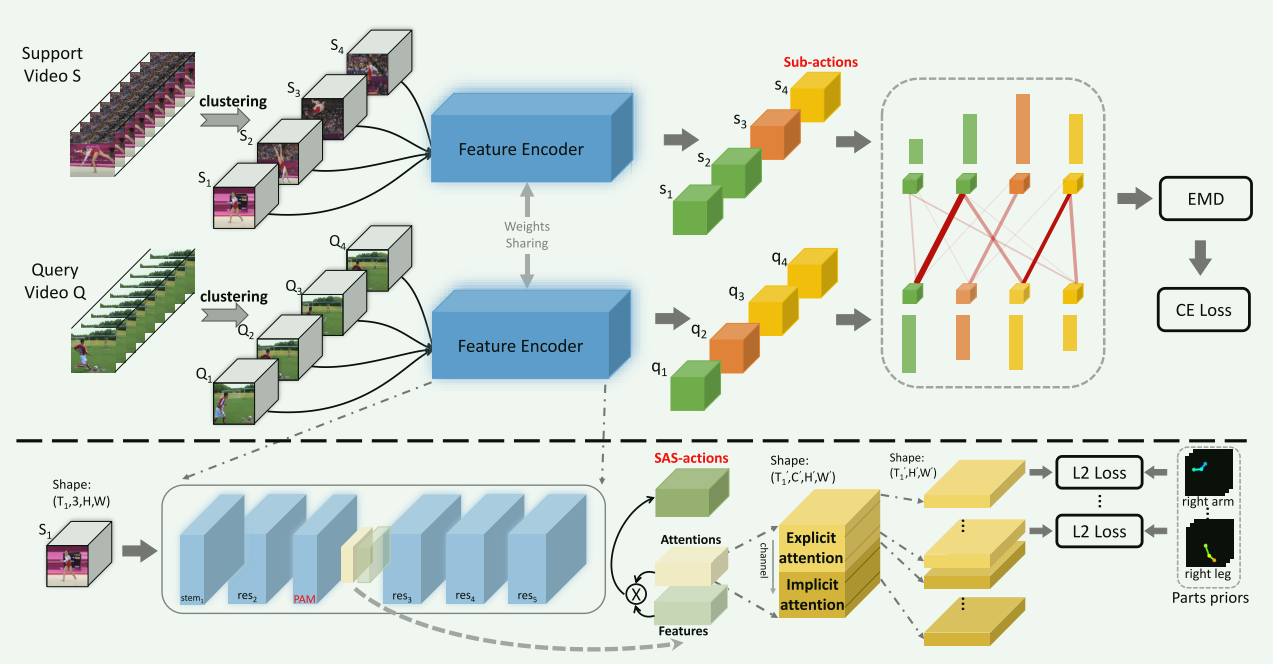
- 上图展示了本文所提出的小样本视频动作识别模型的总体框架,该模型首先通过聚类将复杂的动作划分为若干子动作,然后通过部分注意模块(Parts Attention Module, PAM)进一步将子动作分解为更细粒度的SAS动作,这些细粒度SAS动作由显式SAS动作和隐式SAS动作组成。前者对应于预定义的身体部位,后者对应于其他与行动相关的线索,如上下文信息。此外,本文修改了传统的分层聚类以将视频分割成时间长度变化的子动作,而不是将视频序列均等地分割成剪辑。因此,相似的视频帧被收集,并且连续语义被一起保留在子动作内。而且,考虑到直接对齐本地表示沿着时间维度不能很好地处理时间无关的动作样本,本文采用地球移动器的距离(EMD)作为距离函数,以匹配子动作表示,以更好地比较细粒度的模式,实现视频片段内部的时序序列在聚类的子动作中得到很好的保留,而在片段之间时序序列被优化EMD距离的过程所忽略。最后,从EMD中获得匹配相似度后,采用softmax函数来计算各种动作的概率。
- 模型结构:图中展示了本文提出的层次组合表示(Hierarchical Compositional representations, HCR)模型。具体而言,首先将视频切割为多个不同长度的子动作片段,并提取了每个片段的时空特征。此外,利用(Parts Attention Module)PAM模块将每个通道作为SAS动作,并划分为显示(Explicit)SAS动作(即身体部位)和隐式(Implicit)SAS动作(即上下文信息)。最后,利用EMD距离函数计算了支持集和查询集的子动作表示序列之间的相似性,相似性得分送入Softmax层映射到样本动作分类的概率分布中,计算公式如下:
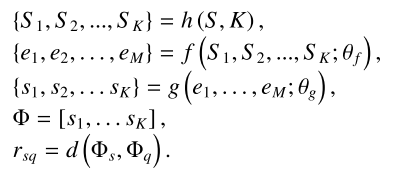
关键技术分析
1. 层次组合表示
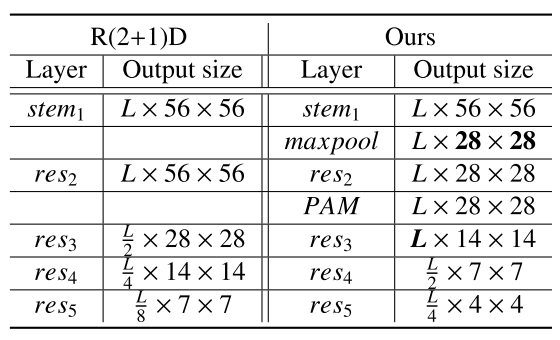
该方法将视频动作进行了两次划分:第一次是根据人通常将动作分解来识别动作的原理,将复杂动作划分为多个子动作;第二次是沿着空间维度,将子动作划分为细粒度的SAS动作。经过两次划分后可以实现基本动作(训练)与新动作(测试)之间的信息传递。网络使用的是Efficient R(2+1)D网络,其结构如下表:
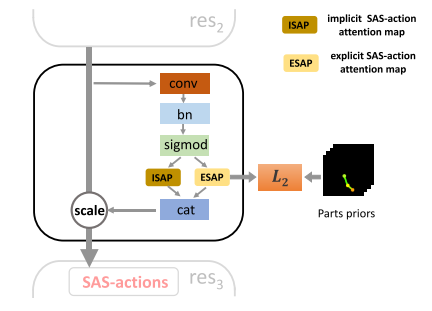
在原有网络中,做了 修改:(1)添加了PAM模块,从而帮助模型学习SAS动作,结构图如下图:
(2)增加了空间下采样(最大池化层);(3)删除了时间下采样。下图为可视化预测的SAS动作注意力图:
2. EMD度量
在度量支持集和查询集之间的距离时,如果直接度量全局表示,则会丢失时序信息,如果严格匹配局部表示,则无法处理一些与时间先后有关的动作。因此采用Earth Mover’s Distance(EMD)来衡量两个子动作的距离。EMD距离评估了在向量空间中两个多维度分布的区别。在计算支持集和查询集中子动作的特征表示序列距离时,首先计算了自动做特征,然后将子动作特征作为一个节点(类似于生产者和消费者),最后两个动作视频u和v之间的距离看作是两个对应的子动作表示序列的最佳匹配成本。
实验分析
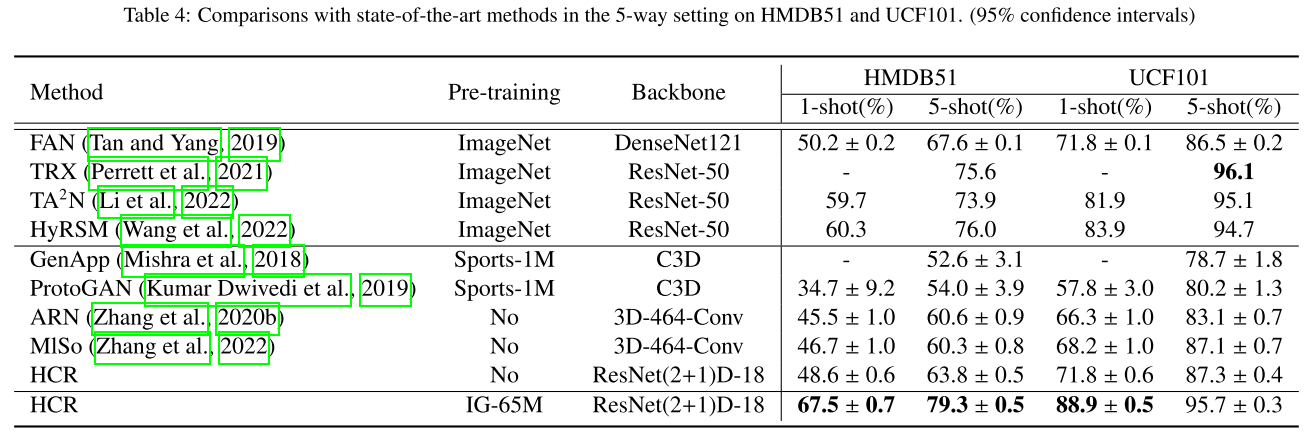
本文采用的数据集是HMDB512、UCF101和Kinetics。本文在5-way上与当前的SOTA进行了比较。结果如上图所示。在没有对任何数据集进行预训练的情况下,本文方法在1-shot中在HMDB51和UCF101数据集上分别超过ARN 3.1%和5.5%。此外,本文方法优于MlSo,并且在HMDB51和UCF101数据集上分别增加到48.6%和71.8%。
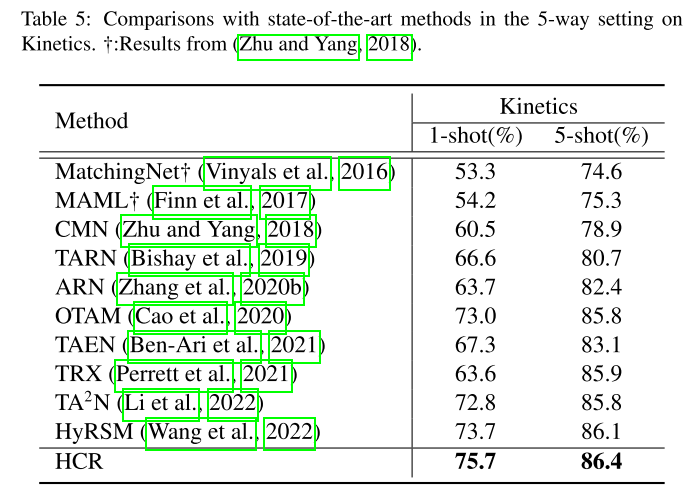 在上表中,遵循Kinetics-CMN协议(Zhu和Yang,2018),本文优于所有最近的方法,例如,TRX和HyRSM,并取得了国家的最先进的动力学结果,这再次证明了我们的方法的优越性。
在上表中,遵循Kinetics-CMN协议(Zhu和Yang,2018),本文优于所有最近的方法,例如,TRX和HyRSM,并取得了国家的最先进的动力学结果,这再次证明了我们的方法的优越性。
未来工作
- 在未来的科研过程中,对于任何应用型研究,都可以模仿人类的思想去解决。比如本文通过模仿人类在识别动作时通常将动作分为一些小的细节,动作识别模型也将视频中的动作进行两次划分,进行细粒度的识别。
- 本文在计算动作之间距离的时候,使用的是EMD,并不是计算机领域中常用的算法。因此,在平时的研究工作中可以扩展知识域,利用其它领域中与自己研究任务相同或相似原理的方法来解决当前任务的瓶颈问题。
论文获取
上述论文和代码快捷下载
关注公众号 AI八倍镜。后台回复:HCR,即可一步下载上述论文以及开源代码。
共 2 条评论关于 “视频行为识别(二)——小样本动作识别的分层组合表示”