视频行为识别(一)——综述
分类: 人工智能、学习笔记 3064 2
Deep Neural Networks in Video Human Action Recognition: A Review
本次分享的文章是2023年收录在计算机视觉领域的顶刊“CVPR”(级别:视觉类TOP)期刊上。该期刊详细信息可关注公众号 AI八倍镜 点击菜单项查询。
论文地址:https://arxiv.org/abs/2305.15692
主要贡献
- 包含了2020年至2022年内发表的所有结合人体行为和深度神经网络的论文:在数据层面,包含了骨架、RGB、RGB+D、光流、深度图等数据格式的论文;在任务层面,包含了异常行为识别、场景图关系分析、行人再识别等任务的论文;从网络架构层面,包含了独立神经网络模型和联合神经网络模型的论文,。
- 本论文内容结构:(1)介绍了现有综述的工作和深度学习在基于视频的行为识别任务中的应用。(2)介绍了相关数据集和相关说明;(3)介绍了基于深度学习的人体行为识别任务中较为流行的方法;(4)叙述了人体行为识别的应用场景;(5)介绍了深度学习的网络框架和他们的结构,以及各框架之间的比较;(6)阐述了利用基于时间模块来解决行为识别任务中时序敏感问题的解决方法的总述;(7)讲述了具有双流和多流结构的3D神经网络;(8)分析了人体行为识别任务中的瓶颈问题和将来应该进一步优化和加强的方向。(9)总结全文,分析了基于深度学习方法在应用中的前景。

数据集
视频行为识别的数据集主要来源于工业或者一些网站,如YouTube、监控系统、大学等。随着视频媒体的快速发展,视频行为识别数据集的规模也在不断扩大。
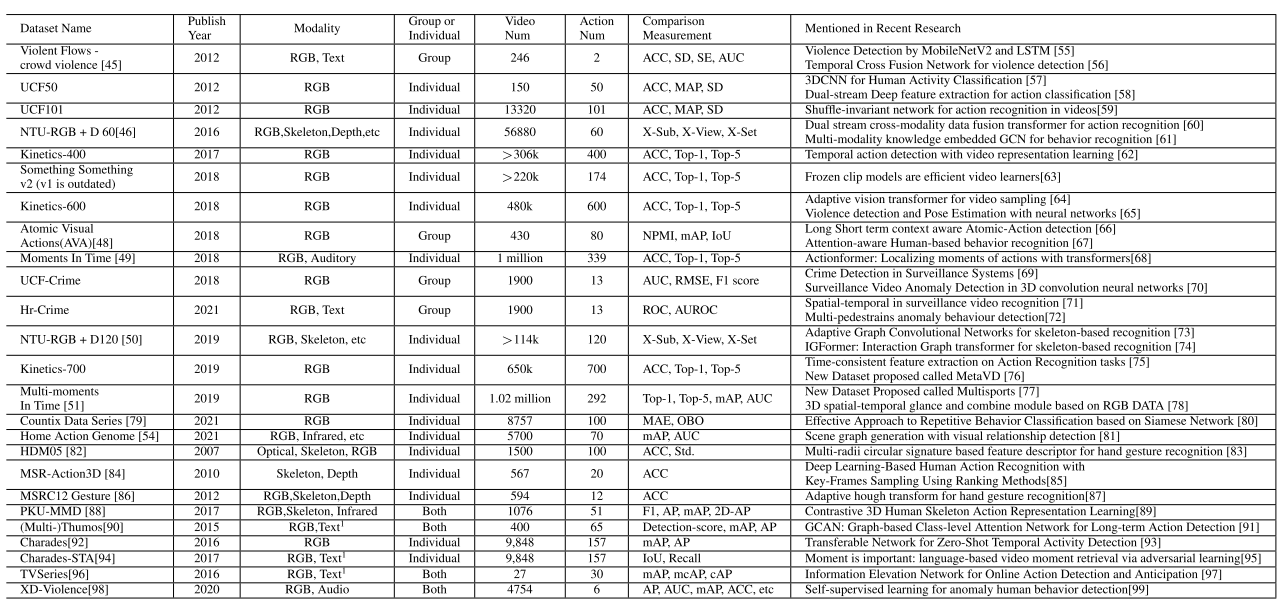
对于最早的历史数据集而言,最早再2012年发布了Violent Flows-crowd violence、UCF50和UCF101等数据集。前者是一个真实的群体暴力视频剪辑数据集,包含246个视频,平均视频时长为3.6秒。UCF50和UCF101中末尾的数字表示了数据集中行为类别的数量,这两类数据集将每个类别划分为25个组,每个组有4个视频。该数据集的缺点是视频的标签较少,而且部分视频并非是真实环境记录。此外,2018年提出了UCF-Crime数据集,主要包含了异常行为数据集的真实监控视频,有13种异常行为和1900个相关视频,其中1610个视频作为训练数据,290个视频作为测试数据。此外,2016年NTU RGB+D构造了NTU RGB+D数据集、2017年提出了Kinetics-400数据集、2018年提出了Kinetics-600和2019年提出了Kinetics-700,2018年还提出了Moments in Time (Mit)数据集。此外,CVPR2020和CVPR2021分别提出了Countix Data数据集和Home Action Genome数据集,其中Countix Data数据集收集了一些野生视频,是Kinetic数据集的一个子集,但比QUVA数据集(包含各类运动的视频数据集)大90倍;Home Action Genome数据集包含了多视图和多模态的数据,包含5700个视频,并将所有视频划分为75种活动,下图是所有数据集之间的对比。
深度学习方法与评价指标
对比学习
对比学习可以用于监督和无监督方法。该方法是在大批量数据集的情况下提出的,当它用于人体动作识别的无监督学习时,需要更多的训练步骤,这个框架的初步提议是在2020年解决视觉表示。对比学习也可以用于监控视频中的异常检测任务中,目标是使具有相同类的样本彼此接近,使具有不同类的样本之间的间隔距离变大。在异常检测任务中提出的框架是通过捕获语义特征的区别来识别正常与异常,如果新输入的样本被识别为正常行为的阈值内,则模型将其判定为正常动作。当然,对于人与环境交互的环境中,模型也将利用对比学习来识别固定模式和上下文环境信息。
评价指标
在行为识别任务中官方使用的评价指标有Average Precision(AP)和mean Average Precision(AP)两类,具体使用哪种取决于行为识别任务的模态,如NTU-RGB+D数据集中更多使用的是跨试图、跨主题的评价指标。此外,目前常用的指标还包括特定类别中行为识别的Top 1准确度或Top 5的准确度,同样,指标的评估还取决于监督学习中生成的特征和分类器的选择,如准确率、召回率和F1指数。此外,损失函数也是可计算的,如:
![]()
该函数根据随机变量定义了交互损失,其中X和Y为交互信息。
损失函数可以根据不同的场景来设计,例如重建损失函数、交叉熵函数、均方误差或类别和分类之间的类域损失。
D和2D骨架(多模态)行为识别
基于2D和3D骨架的姿态估计已经用在了多个场景中,人体关节姿势估计的原始设计是将提取到的骨架数据作为模型输入图像范围内的模态数据之一, 该方法在当前的研究任务中仍然很受欢迎。
SPML模型在Human3.6M数据集和3DPW数据集中,提取了3D格式的骨架,且在3D空间中的人类行为识别任务中,2D和3D骨架取得了较好的效果。深度学习方法作为计算机视觉任务中的一种模式,专注于特征提取,以完成分类,回归或预测任务。而骨架行为识别的工作流程基本上是用于进一步行为预测或下游任务的端到端学习或机器学习的流水线工作。
领域自适应
在源数据集和目标数据集上,利用领域自适应能够为人类行为识别任务从源到目标或从目标到源提供一种简洁方式。无监督方法提出了新的多数据源,包括用于语义识别的无监督域自适应,而不是单源无监督域自适应(UDA),该研究工作通过生成用于模式识别的合成图像和数据,并通过GAN中的鉴别器识别来分离真实的数据和合成数据,从而利用对抗域自适应。
一项工作(具体看原文参考文献114)调查了无监督域自适应能力,研究表明在2个模型的竞争过程中生成对抗DA,能够提高识别任务的准确性。在另一项研究工作[111]中表明,从源域中提取鉴别特征,可以用于目标域的行为模式识别。
在领域自适应中,如何将来自标记数据的源数据集信息应用到目标未标记数据上,从而用于可识别的特征表示和识别是一项比较重要的工作,这也是将来可改善的一个方向。在此过程中涉及两个关键概念,一个是领域迁移,即把识别信息从一个域转移或传递到另一个域;另一个概念是对抗适应,它在GAN(生成对抗网络)和无监督域适应的许多组合中被提及。
应用场景和方法
随着视频行为识别技术的应用,这篇综述提到了一项研究[119],其主要以老年痴呆症患者为研究对象,针对老年痴呆症患者的特殊行为类型,研究其异常行为的预测和预防。
 场景图是指将物体放置在一个立体的环境中,能确定现有物体的地理信息,如前面、后面、侧面等,最早场景图在人物关系抽取中提到。而事件指的是人类或运动之间的互动,如拿起杯子,拿着物体和携带物品,其涉及时间序列。时间序列用于移动对象而不是静态事件,特别是对于视频内容分析中利用场景图来提取人与人和人与象的关系时。但是,当场景图没有考虑同步的人类行为时,场景图的局限性是显而易见的,例如,在听智能手机的同时拿着杯子。
场景图是指将物体放置在一个立体的环境中,能确定现有物体的地理信息,如前面、后面、侧面等,最早场景图在人物关系抽取中提到。而事件指的是人类或运动之间的互动,如拿起杯子,拿着物体和携带物品,其涉及时间序列。时间序列用于移动对象而不是静态事件,特别是对于视频内容分析中利用场景图来提取人与人和人与象的关系时。但是,当场景图没有考虑同步的人类行为时,场景图的局限性是显而易见的,例如,在听智能手机的同时拿着杯子。
提取行为识别描述符

行为识别描述符是指当视频序列类型包括离散和连续的人体部位描述符时,行为识别的学习和识别特征。卷积神经网络是深度学习方法中的主要框架特征提取过程。在研究工作中[121],他们利用GRU基于视频序列帧生成人类字幕,这可以实现时间序列上的识别任务。如上图所示,来自多个数据集的一些行为被分组在一起以用于行为分类任务。
深度神经网络及其比较
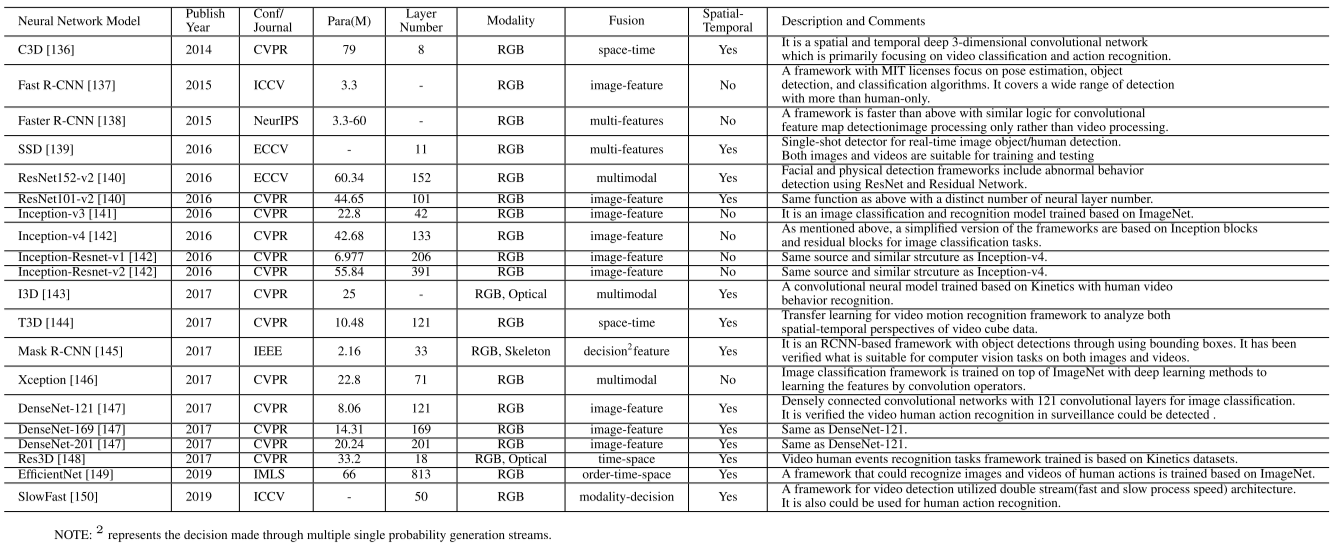
许多深度学习骨干和深度神经网络已用于动作分析任务,如表所示。基于深度学习的方法试图通过堆叠更多的神经层来进行特征提取,而不是机器学习算法来提高识别精度。
总结与展望
首先,这篇综述从空间和时间的角度研究了现有最新的视频人体行为识别发深度学习方法。在过去几年的研究中,包括RGB、RGB-D、光流、灰度和基于骨架的数据类型都被用于视频内容分析。除了空间信息之外,视频信息还提供了用于人类动作识别的上下文,主要是当动作取决于环境时,视频识别被用于异常检测和分析。时间信息提供了行为的上下文,而不是单个帧。然后从数学和技术两个角度对视频行为识别的现有研究成果进行了总结。在深度神经网络的使用中提到了多种类型的架构和数据模态,包括单独和混合网络。最后,这篇综述的调查工作提供了现有的网络和数据集的概述和未来的研究领域。
上述论文和代码快捷下载
关注公众号 AI八倍镜,后台回复:VHAR,即可一步下载上述论文(Deep Neural Networks in Video Human Action Recognition: A Review)。
共 2 条评论关于 “视频行为识别(一)——综述”